
 La plus souvent possible, je participe aux événements qu’organise le Labo de l’Edition. Le fait que le Labo soit situé à deux stations de métro de la place d’Italie où je travaille me facilite grandement les choses. Jeudi dernier, je n’aurais raté la soirée pour rien au monde, même si le Labo avait déménagé à Cergy ou  bien à Trappes, à Etampes ou à Dourdan… J’aurais pris le RER C, tout simplement, ce qui m’aurait bien préparée à une soirée toute entière consacrée à une belle réalisation éditoriale, associant  un livre imprimé et une application nommée : VuDuRERC.
La plus souvent possible, je participe aux événements qu’organise le Labo de l’Edition. Le fait que le Labo soit situé à deux stations de métro de la place d’Italie où je travaille me facilite grandement les choses. Jeudi dernier, je n’aurais raté la soirée pour rien au monde, même si le Labo avait déménagé à Cergy ou  bien à Trappes, à Etampes ou à Dourdan… J’aurais pris le RER C, tout simplement, ce qui m’aurait bien préparée à une soirée toute entière consacrée à une belle réalisation éditoriale, associant  un livre imprimé et une application nommée : VuDuRERC.
À partir d’une idée qui a dû venir à l’esprit de bien des voyageurs, rêvant en regardant le paysage défiler à grande vitesse par la fenêtre du TGV, l’écrivain et mémorialiste Olivier Boudot avait déjà conçu et réalisé le livre : Paris-Lyon vu du train. De cette rêverie souvent interrogative (Que sont ces lieux ? Qu’y a -t-il derrière cette colline ? Est-ce que ce petit manoir est habité ? etc.), Olivier a décidé de faire le point de départ d’un patient travail d’enquête, qu’il décrit sur le site consacré au livre. Sylvie Tissot, informaticienne et chercheuse en informatique, réalise en complément du livre une application permettant de géo-localiser les pages du livre.
Autrefois, un trajet en train était une sorte de parenthèse temporelle, durant laquelle dominait une ignorance presque complète des régions traversées. Si en voiture les panneaux routiers permettent de relier facilement un emplacement donné à un point de la carte que l’on déplie, le voyage en train n’était documenté que par le nom des gares, et, dans le cas des TGV, celles-ci sont rares. De longues portions de trajet demeuraient « silencieuses », n’offrant d’autre repère que celui de la forme du paysage et des constructions.  Désormais, pour peu que la couverture 3G soit au rendez-vous, on peut suivre le déplacement du train qui nous transporte sur une carte, et trouver sur le web des informations sur les lieux traversés. Cependant on ne trouve pas « tout » sur le web.
La démarche patiente et passionnée d’Olivier Boudot et de son complice géographe Jean-François Coulais,  et le dispositif de mise en images du trajet, décrit ici, aboutissent à un objet éditorial singulier, un véritable guide de voyage, un livre qui est non seulement destiné à apporter au voyageur des renseignements, mais propose également une vision et raconte des histoires, qui se déploient aussi bien dans l’espace que dans le temps.
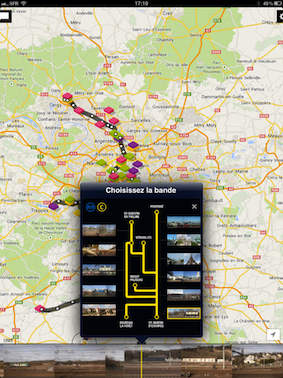
Après Paris-Lyon vu du train, Olivier Boudot publie Vu du RER-C, à partir d’un concept identique. Le livre est présenté ainsi :
« A mi-chemin entre le livre et le guide, Vu du RER C propose 256 pages d’une étonnante promenade le long de la ligne. Au menu : patrimoine architectural, culturel et touristique, balades et traversée des paysages. Vous rencontrerez également des artisans, des voyageurs et des cheminots, dont vous découvrirez les métiers. »
L’application, développée par Sylvie Tissot, et dont le design est réalisé par l’agence Nodesign, va au-delà d’un outil de géo-localisation des pages du livre. Le concept s’est développé dans deux directions, l’une qui documente le passé de l’Ile de France, l’autre le présent.
D’une part, il est possible d’accéder aux textes d’Olivier Boudot et de convoquer des images du passé, issues de différentes sources : collection de cartes postales anciennes de la ville d’Issy-les-Moulineaux, images de la médiathèque SNCF et de l’INA. D’autre part, les usagers de la ligne sont invités à ajouter leurs propres documents, et, via leurs APIs respectives, à échanger des messages Twitter ou à accéder aux horaires des prochains trains.
Chargé d’animer la communauté des utilisateurs de l’application, Omer Pesquer, connu par ailleurs  pour son engagement dans Muzeonum comme pour son superbe générateur de titres, utilise le compte twitter @vudurerc et le compte Facebook dont il donne le lien pendant son livetweet de la présentation :
#binome le compte Facebook de @vudurerc https://t.co/4bnMWLeoOa
— Omer Pesquer (@_omr) October 3, 2013
Le prototype de l’application, téléchargeable ici, a été présenté lors de l’événement Futur en Seine, et financé par la région Ile de France.
La multiplication des parcours de lectures, la décision de proposer différents filtres pour l’accès aux différents éléments, conduisent à rendre disponibles un grande quantité d’éléments, qui viennent s’ajouter à ceux créés par l’auteur et déjà présents dans le livre. L‘identification, l’acquisition, le traitement et l’intégration des médias (vidéos, images, sons) consomment une très grande part du budget et du planning dans un projet multimédia interactif. La recherche de sources iconographiques, de gisements de données accessibles (de plus en plus nombreuses aujourd’hui avec le mouvement Open Data) est un préalable à de tels projets. Et le code est ce qui va permettre non seulement d’aller chercher les données, mais aussi  d’effectuer leur mise en écran, de leur donner une forme, et de régler les conditions de leur affichage.
Les auteurs/codeurs de VuDuRERC  ont su mettre les capacités des mobiles au service de l’imagination sans tomber dans le systématique, à travers une application fluide et sensible, poétique et ludique, qui n’est pas sans me faire penser à deux autres réalisations dont j’ai parlé dans ce blog :
– l’une proposée en 2008 par Penguin, dans le cadre de l’expérimentation We tell stories : on retrouve dans ce projet l’idée de géo-localisation, et celle d’une collaboration auteur / codeur .
– l’autre, j’en ai parlé cet été, c’est Hi, ce réseau social qui incite à écrire à partir du lieu où l’on se géo-localise. Pourquoi d’ailleurs, ne pas proposer aux concepteurs de Hi de permettre à leurs utilisateurs d’enrichir de leurs textes et photos l’application VuDuRERC ?
Il y en a bien d’autres, certainement, que n’ont pas fini d’explorer ceux que les cartes font rêver, tout comme ceux qui, en voyage, rêvent aux cartes autant qu’aux territoires. N’hésitez pas à les signaler en commentaire.




![Goodreads' success story [infographic] | Ebook Friendly](http://ebookfriendly.com/wp-content/uploads/2013/03/Goodreads-success-story-infographic.jpg "Goodreads' success story [infographic] | Ebook Friendly")









